 搜索
搜索  英文
英文  联系我们
联系我们  首页
首页 
近日,我院王琦教授团队在推理加速与生成式人工智能底层架构演进等领域取得重要突破,相关研究论文《Statistically Optimal Scaling for Token Merging in Transformers》与《σ: Sigmoid Modulation for Ultra High Resolution Diffusion》被人工智能领域CCF-A类顶级国际会议 ICML(International Conference on Machine Learning)2026录用。
基于统计最优缩放的Transformer词元合并
在视觉大模型推理加速中,词元合并通过聚合相似的词元来缩短序列长度 。然而,在极高的压缩率下,这种方法会严重扭曲注意力输出,引发残差流中的协变量偏移,从而导致模型性能崩溃。现有的启发式方法虽然能在轻度压缩时起效,但在激进的压缩比例下,由于未能从根本上解决能量漂移和注意力分布偏差等问题,性能会急剧下降。
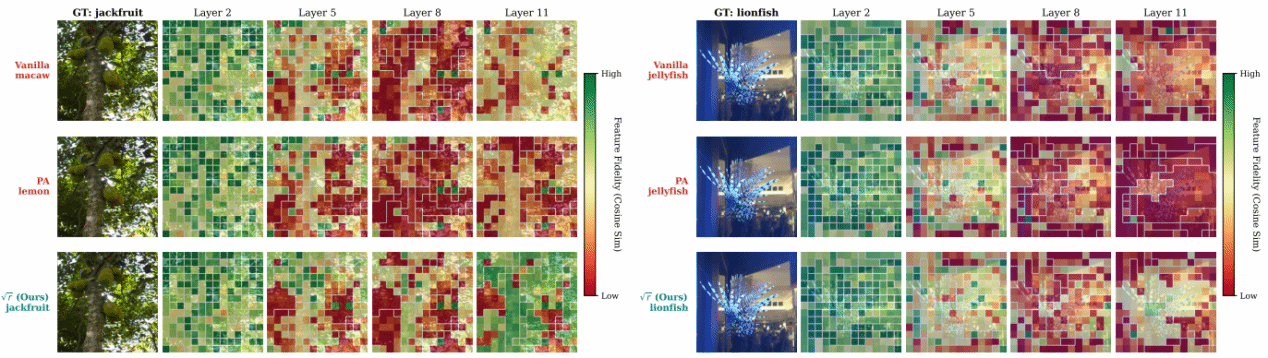
图1:不同策略的特征保真度可视化
针对这一难题,团队将词元合并重新构建为高维空间中的统计重建问题。研究创新性地提出了渐近径向-角度分解分析框架,巧妙地将幅度扭曲与分布扭曲进行了解耦。在有限二阶矩的最小假设下,团队通过最小化这一分解风险,推导出了由单一缩放定律主导的闭式最优修正方案:同时对合并后的值进行缩放,并将合并后的逻辑值向聚类大小先验收缩。该方案不仅保持了模型的能量平衡,还恢复了其分布保真度。大量基于视觉Transformer的实验表明,该方法在各级压缩水平下均展现出了卓越的准确率和鲁棒性。
论文第一作者为博士生周情,通讯作者为王琦教授。
基于S型调度函数的超高分辨率扩散框架
虽然扩散Transformer(DiT)在图像生成上展现出了惊艳的高保真度,但在超高分辨率下进行训练的计算成本极其高昂,因此业界迫切需要强大的推理期分辨率外推方法。现有的外推方法大多是“尺度无关”的,它们忽略了扩散过程中从低频结构构建到高频纹理细化的谱演化本质上是高度依赖于尺度的。以信噪比(SNR)为主导的视角来看,扩散模型总是先收敛低频的全局结构;并且当分辨率扩大时,高分辨率结构应该在更早的时间步完成收敛。如果盲目使用僵化统一的静态外推策略,将导致严重的谱不对齐,进而引发结构崩塌或纹理退化。
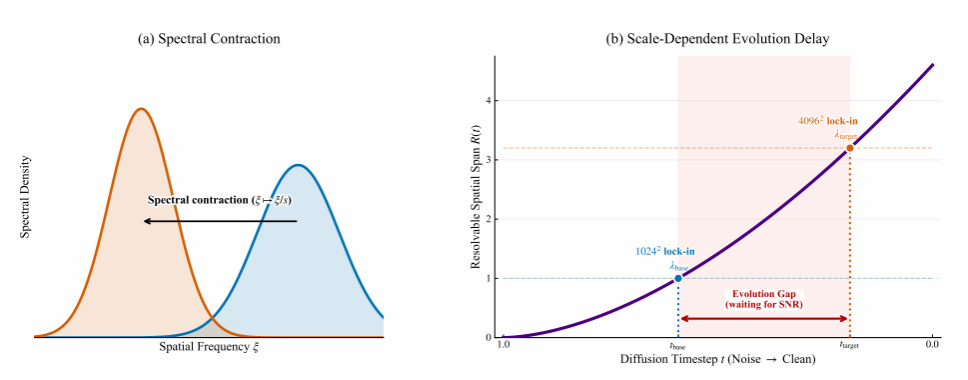
图2:尺度相关的谱演化
为此,团队提出了一种无需训练的框架,利用S型调度函数对外推过程进行尺度自适应校准。该框架包含了两个核心机制:一是解耦的几何中心对齐机制,通过同步转换时机来锚定全局结构,确保高分辨率结构能够尽早收敛;二是等方差率自适应机制,用于精准缩放转换速度,保障特征的平滑交接。在保持总推理步数与基础模型完全相同的情况下,框架有效纠正了谱偏差,实现了高达1600万像素的外推生成,在各项标准基准测试中均达到了SOTA水平。
论文第一作者为博士生赵炳轩,通讯作者为王琦教授。
更多研究成果详见团队主页:https://crabwq.github.io/
(文:周情,审核:赵斌)